Show HN: LLMs suck at writing integration code… for now
We gave LLMs API documentation and asked them to write code that makes actual API calls. Things like "create a Stripe customer" or "send a Slack message". We're not testing if they can use SDKs; we're testing if they can write raw HTTP requests (with proper auth, headers, body formatting) that actually work when executed against real API endpoints and can extract relevant information from that response.
tl:dr: LLMs suck at writing code to use APIs.
We ran 630 integration tests across 21 common APIs (Stripe, Slack, GitHub, etc.) using 6 different LLMs. Here are our key findings:
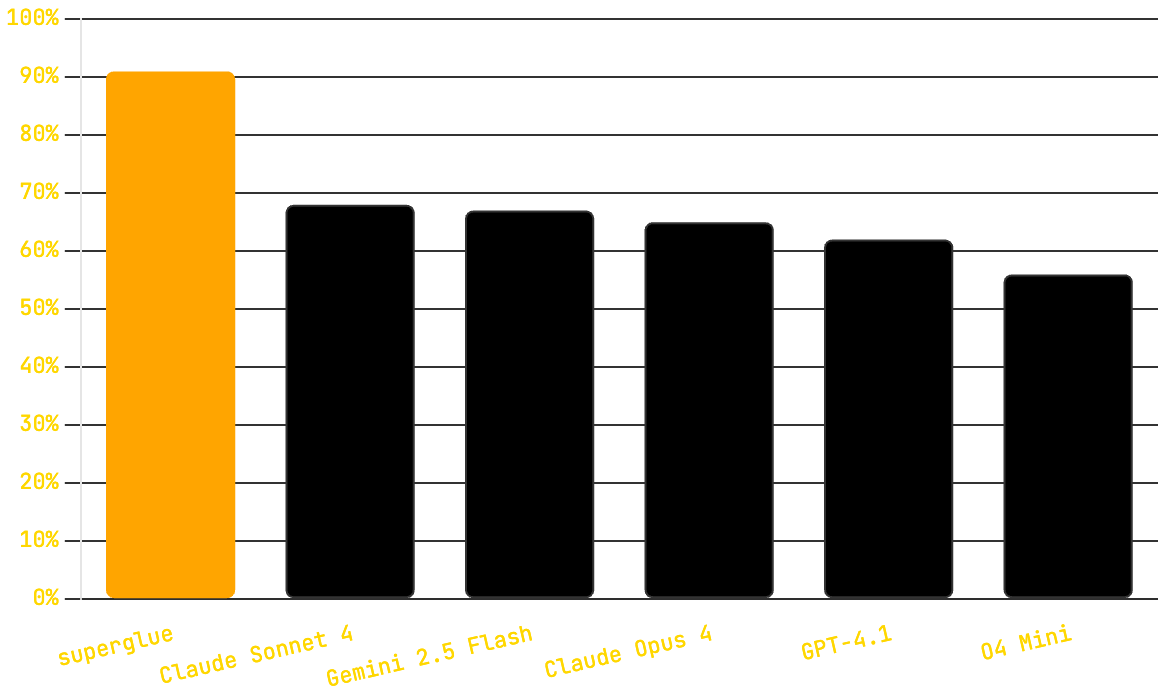
- Best general LLM: 68% success rate. That's 1 in 3 API calls failing, which most would agree isn’t viable in production
- Our integration layer scored a 91% success rate, showing us that just throwing bigger/better LLMs at the problem won't solve it.
- Only 6 out of 21 APIs worked 100% of the time, every other API had failures.
- Anthropic’s models are significantly better at building API integrations than other providers.
Here is the results chart: https://superglue.ai/files/performance.png
{kind=link}
What made LLMs fail:
- Lack of context (LLMs are just not great at understanding what API endpoints exist and what they do, even if you give them documentation which we did)
- Multi-step workflows (chaining API calls)
- Complex API design: APIs like Square, PostHog, Asana (Forcing project selection among other things trips llms over)
We've open-sourced the benchmark so you can test any API and see where it ranks: https://github.com/superglue-ai/superglue/tree/main/packages...
Check out the repo, consider giving it a star, or see the full ranking at https://superglue.ai/api-ranking/.
If you're building agents that need reliable API access, we'd love to hear your approach, or you can try our integration layer at superglue.ai.
Next up: benchmarking MCP.
I can’t tell from the description if the LLMs are allowed to try and then correct based on any errors received.
Though it would be surprising if that helped. Most APIs don’t tell you what you’ve done wrong…